
Giới thiệu
Phương pháp đo phổ khối lượng truyền thống (Mass Spectrometry) yêu cầu ion hóa mẫu (tức là thêm điện tích), sau đó đo độ lệch trong trường điện từ. Từ đó gián tiếp tính ra khối lượng của mẫu. Điều này có thể gây biến đổi mẫu, đặc biệt với các mẫu sinh học.
Các nhà khoa học tại Caltech giới thiệu một phương pháp mới để đo khối lượng các phân tử đơn lẻ thông qua công nghệ nano và trí tuệ nhân tạo. Phương pháp này được gọi là: Phổ khối lượng nano cơ điện dạng dấu vân tay (fingerprint nanoelectromechanical mass spectrometry)
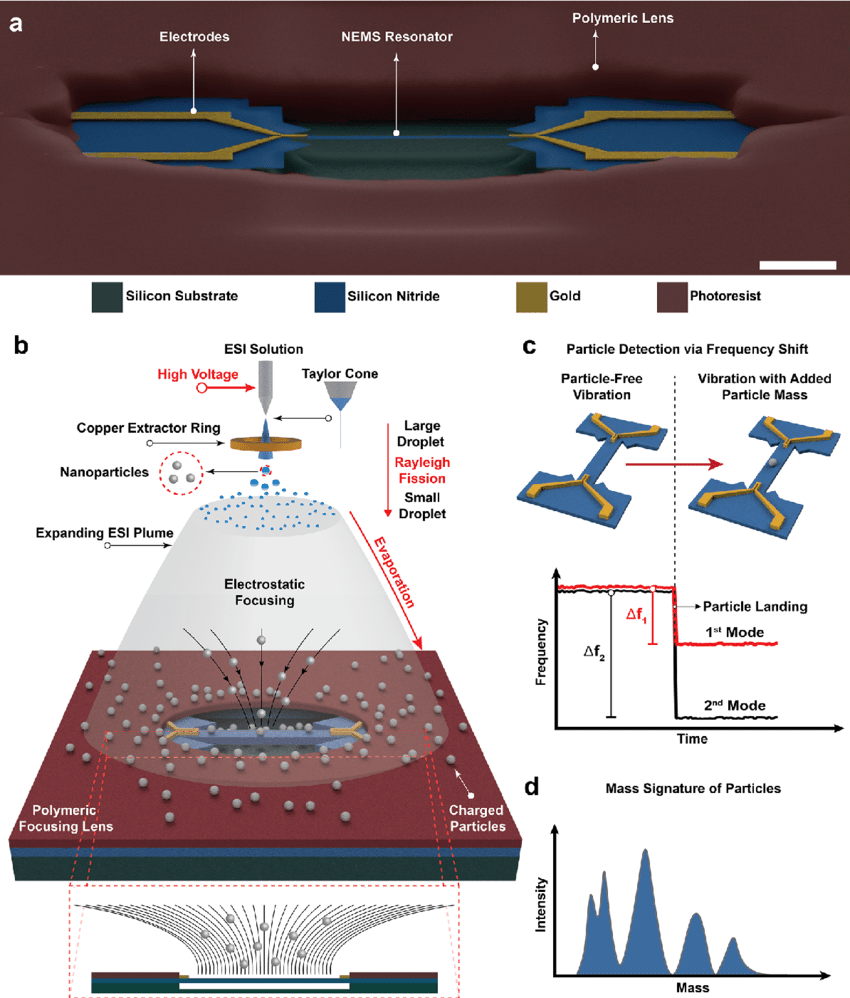
Giống như cách bạn xác định dấu vân tay người, các phân tử cũng có “dấu vân tay” riêng dựa trên sự thay đổi tần số, khi chúng tương tác với thiết bị NEMS. Khi một phân tử bám lên thiết bị, tần số dao động thay đổi theo cách duy nhất, cho phép các nhà khoa học xác định phân tử đó mà không cần phá hủy nó.
Nanoelectromechanical Systems (NEMS): Các thiết bị ở cấp độ nano có thể dao động với tần số cụ thể khi bị tác động. Các thiết bị này hoạt động giống như dây đàn, khi mẫu bám vào, tần số dao động sẽ thay đổi tùy thuộc vào khối lượng của mẫu.
Phương pháp cũ (Phổ khối lượng truyền thống)
- Cần ion hóa mẫu trước khi đo
- Có thể làm biến đổi cấu trúc mẫu, không phù hợp mẫu sinh học
- Cần kích thước mẫu lớn
- Ứng dụng: hóa học, phân tích cơ bản
Phương pháp mới (Phổ khối lượng nano dạng dấu vân tay)
- Không cần ion hóa, giảm nguy cơ biến đổi mẫu
- Giữ nguyên cấu trúc tự nhiên của mẫu, đặc biệt hữu ích cho nghiên cứu sinh học
- Độ chính xác cao ở cấp nano, thích hợp cho đo mẫu phân tử đơn lẻ
- Ứng dụng: Sinh học, phân tích hệ protein (proteome)
Ví dụ cụ thể
Giả sử các nhà khoa học muốn đo mẫu protein A. Họ sẽ đặt protein A lên thiết bị NEMS hàng trăm hoặc thậm chí hàng ngàn lần, thu được các vector dấu vân tay từ các phép đo. Tập hợp các vector này sẽ tạo thành một mẫu hình thống kê mà AI có thể học. Khi gặp protein A trong các lần đo mới, AI sẽ đối chiếu vector đo được với các vector đã lưu trữ để xác định đây có phải là protein A hay không, dựa trên sự tương đồng về đặc điểm trong vector.
Quy trình tạo tập dữ liệu vector cho protein
- Chọn các mẫu protein đã biết: Các nhà khoa học bắt đầu với các mẫu protein mà khối lượng và tính chất của chúng đã được xác định từ trước. Điều này giúp họ biết chính xác đặc điểm của protein nào đang được đo, làm nền tảng cho quá trình huấn luyện AI.
- Thực hiện nhiều lần đo: Với mỗi protein, họ sẽ tiến hành đo nhiều lần trong các điều kiện khác nhau (ví dụ: thay đổi vị trí đặt trên thiết bị NEMS, nhiệt độ, áp suất), nhằm tạo ra nhiều vector đại diện cho cùng một loại protein. Mỗi lần đo có thể cho ra một vector khác nhau một chút do nhiễu và sai số tự nhiên, nhưng khi đo nhiều lần, họ sẽ tạo ra một tập hợp dữ liệu phong phú.
- Trích xuất và lưu trữ vector “dấu vân tay”: Các vector này được lưu trữ trong một cơ sở dữ liệu làm “dấu vân tay” độc nhất cho từng loại protein. AI sau đó sẽ học từ những vector này để hiểu được các đặc điểm đặc trưng của từng loại protein, bao gồm cả sự biến động nhỏ do sai số.
- Huấn luyện AI với dữ liệu đã biết: Bằng cách huấn luyện AI trên tập dữ liệu vector “dấu vân tay” của nhiều loại protein khác nhau. AI sẽ học các đặc trưng và mẫu hình riêng biệt cho từng protein, giúp nó có khả năng dự đoán và phân loại các protein mới với độ chính xác cao.
- Kiểm tra và hiệu chỉnh AI: Sau khi huấn luyện, các nhà khoa học sẽ kiểm tra AI bằng cách đưa vào các mẫu protein chưa từng được AI “nhìn thấy” nhưng có trong cơ sở dữ liệu, để xác minh xem AI có thể nhận diện chính xác hay không. Nếu AI nhận diện sai, mô hình sẽ được điều chỉnh để tăng độ chính xác.
Vai trò của AI:
Đây là một ví dụ điển hình của việc áp dụng AI trong khoa học thực nghiệm, nơi các kỹ thuật học máy giúp xử lý dữ liệu phức tạp và biến đổi để đạt được kết quả đáng tin cậy.
- 1. Trích xuất đặc trưng: Hàng ngàn phép đo thực hiện trên NEMS tạo thành các vector. AI sử dụng mô hình học sâu (deep learning) để “nhìn” toàn bộ vector, lọc ra các đặc trưng tiềm ẩn. Từ đó tạo ra “dấu vân tay” riêng biệt cho từng loại phân tử.
- 2. Phân loại: Mỗi phân tử có một vector đặc trưng. Khi cần xác định một phân tử mới, nếu vector của phân tử mới gần giống với một vector có trong cơ sở dữ liệu, AI sẽ phân loại phân tử đó theo dữ liệu được lưu trữ trước đó.
- 3. Xử lý nhiễu và sai số: Bằng cách thu thập nhiều phép đo trên cùng một loại phân tử, trong các điều kiện khác nhau, AI xác định được phạm vi sai số và các yếu tố nhiễu đặc thù cho mỗi phân tử. Khi AI đã học được sự phân bổ thống kê của dữ liệu, nó loại trừ các kết quả đo nằm ngoài khoảng giá trị hợp lý, giảm thiểu tác động của phép đo sai.
Tuy nhiên hạn chế vẫn tồn tại: AI chỉ có thể học từ dữ liệu mà nó đã được cung cấp. Nếu có quá nhiều sai số ngẫu nhiên hoặc không đoán trước được trong dữ liệu ban đầu, AI có thể khó khăn trong việc phân biệt giữa các phân tử có khối lượng gần nhau. Khi đó các nhà khoa học cần sử dụng các phương pháp bổ sung hoặc kỹ thuật tinh chỉnh dữ liệu để tăng độ phân giải của phép đo.
Kết:
Ý nghĩa của nghiên cứu này rất lớn, đặc biệt là trong y học và sinh học. Khả năng đo khối lượng của các phân tử đơn lẻ mà không phá vỡ cấu trúc của chúng, giúp các nhà khoa học hiểu rõ hơn về cơ chế của các bệnh phức tạp và khám phá các phương pháp điều trị mới.
Nếu một loại protein có vai trò đặc biệt trong bệnh ung thư, phương pháp này có thể giúp xác định khối lượng và sự hiện diện của protein đó trong cơ thể người bệnh mà không cần phải phá hủy mẫu, từ đó hỗ trợ việc chẩn đoán và điều trị.
Nghiên cứu này giả định rằng:
Các tần số dao động của thiết bị NEMS có thể được đo và phân tích chính xác ở cấp độ nano.
Các “dấu vân tay” dựa trên tần số dao động là duy nhất cho mỗi phân tử, do đó có thể phân biệt các phân tử khác nhau chỉ qua sự khác biệt về tần số.
Tham khảo: “Data-driven fingerprint nanoelectromechanical mass spectrometry” by John E. Sader, Alfredo Gomez, Adam P. Neumann, Alex Nunn and Michael L. Roukes, 22 October 2024, Nature Communications. DOI: 10.1038/s41467-024-51733-8
профиль с подписчиками https://birzha-akkauntov-online.ru/
безопасная сделка аккаунтов https://marketplace-akkauntov-top.ru
купить аккаунт https://magazin-akkauntov-online.ru/
маркетплейс аккаунтов соцсетей продать аккаунт
перепродажа аккаунтов маркетплейс аккаунтов
услуги по продаже аккаунтов профиль с подписчиками
аккаунт для рекламы аккаунт для рекламы
Account trading platform Database of Accounts for Sale
Marketplace for Ready-Made Accounts Account Acquisition
Guaranteed Accounts Account Purchase
Sell Pre-made Account Account Market
Account Trading Platform Find Accounts for Sale
Account trading platform Ready-Made Accounts for Sale
Purchase Ready-Made Accounts Account Acquisition
Account trading platform Sell accounts
Account Acquisition Website for Buying Accounts
Account Purchase Ready-Made Accounts for Sale
Account Buying Platform Account Catalog
buy accounts buy accounts
purchase ready-made accounts verified accounts for sale
secure account sales account marketplace
online account store buy pre-made account