
Introduce
Traditional mass spectrometry methods require ionizing the sample (i.e. adding an electric charge), then measuring the deflection in the electromagnetic field. This indirectly calculates the mass of the sample. This can cause sample variability, especially with biological samples.
Scientists at Caltech have introduced a new method for measuring the mass of single molecules using nanotechnology and artificial intelligence. The method is called: fingerprint nanoelectromechanical mass spectrometry.
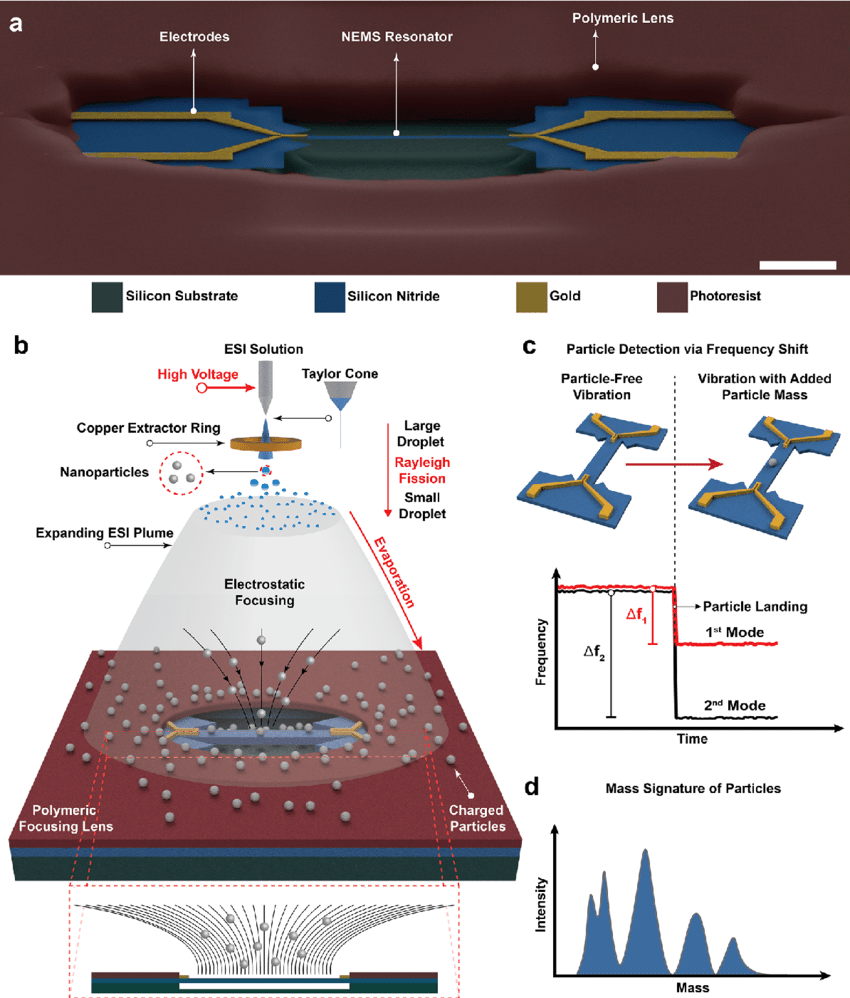
Just like how you identify a human fingerprint, molecules also have their own “fingerprint” based on changes in frequency when they interact with the NEMS device. When a molecule attaches to the device, its vibrational frequency changes in a unique way, allowing scientists to identify that molecule without destroying it.
Nanoelectromechanical Systems (NEMS): Nanoscale devices that can vibrate at a specific frequency when impacted. These devices act like a string, where when a sample is attached, the frequency of the vibration changes depending on the mass of the sample.
Old method (Traditional mass spectrometry)
- Sample ionization is required before measurement.
- May alter sample structure, not suitable for biological samples
- Large sample size required
- Applications: chemistry, fundamental analysis
New Method (Fingerprint Nano-Mass Spectrometry)
- No ionization required, reducing the risk of sample variation
- Preserves the natural structure of the sample, especially useful for biological research
- High precision at nano level, suitable for single molecule sample measurement
- Application: Biology, proteome analysis
Specific examples
Suppose scientists want to measure a sample of protein A. They would place protein A on the NEMS device hundreds or even thousands of times, collecting fingerprint vectors from the measurements. This collection of vectors would form a statistical pattern that the AI could learn. When it encounters protein A in new measurements, the AI would compare the measured vector to the stored vectors to determine whether it is protein A or not, based on the similarity in the vector’s characteristics.
Vector dataset generation process for proteins
- Select known protein samples: Scientists start with protein samples whose masses and properties are already known. This helps them know exactly which protein properties are being measured, which serves as a basis for training the AI.
- Multiple measurements: For each protein, they will take multiple measurements under different conditions (e.g. changing the position on the NEMS device, temperature, pressure), creating multiple vectors representing the same protein. Each measurement may yield a slightly different vector due to noise and natural errors, but by measuring multiple times, they will create a rich data set.
- Extract and store “fingerprint” vectors: These vectors are stored in a database as unique “fingerprints” for each protein. AI then learns from these vectors to understand the unique characteristics of each protein, including small variations due to errors.
- Training AI with known data: By training AI on a dataset of “fingerprint” vectors of many different proteins, the AI will learn the unique features and patterns for each protein, giving it the ability to predict and classify new proteins with high accuracy.
- Testing and calibrating the AI: After training, scientists test the AI by feeding it protein samples that have never been “seen” by the AI but are already in the database, to verify whether the AI can identify them correctly. If the AI makes a mistake, the model is adjusted to improve accuracy.
Role of AI:
This is a prime example of applying AI in experimental science, where machine learning techniques help process complex and variable data to achieve reliable results.
- 1. Feature extraction: Thousands of measurements taken on NEMS form vectors. AI uses deep learning to “see” the entire vector, filtering out hidden features. From there, it creates a unique “fingerprint” for each type of molecule.
- 2. Classification: Each molecule has a characteristic vector. When a new molecule needs to be identified, if the vector of the new molecule is similar to a vector in the database, the AI will classify the molecule according to the previously stored data.
- 3. Handling noise and errors: By collecting multiple measurements on the same molecule, under different conditions, AI determines the error range and noise factors specific to each molecule. Once AI has learned the statistical distribution of the data, it eliminates measurement results that fall outside the reasonable range, minimizing the impact of measurement errors.
However, there are limitations: AI can only learn from the data it has been fed. If there is too much random or unpredictable error in the initial data, AI may have difficulty distinguishing between molecules with similar masses. Scientists then need to use additional methods or data refinement techniques to increase the resolution of the measurement.
Conclude:
The implications of this research are huge, especially in medicine and biology. The ability to measure the mass of individual molecules without breaking down their structure helps scientists better understand the mechanisms of complex diseases and discover new treatments.
If a protein plays a particular role in cancer, this method can help determine the amount and presence of that protein in the patient’s body without destroying the sample, thereby supporting diagnosis and treatment.
This study assumes that:
The oscillation frequencies of NEMS devices can be precisely measured and analyzed at the nanoscale.
The vibrational frequency-based “fingerprints” are unique to each molecule, so it is possible to distinguish different molecules simply by differences in frequency.
Reference: “Data-driven fingerprint nanoelectromechanical mass spectrometry” by John E. Sader, Alfredo Gomez, Adam P. Neumann, Alex Nunn and Michael L. Roukes, 22 October 2024, Nature Communications. DOI: 10.1038/s41467-024-51733-8